|
En los artículos sucesivos que irán apareciendo en la
presente sub-sección se emplearán algunos conceptos que
pueden no resultar del todo familiares para el médico
asistencial; sin embargo, familiarizarnos con ellos
permitirá comprender más en profundidad las ideas
expresadas en los trabajos, al tiempo que redundará en
beneficios indirectos para la práctica clínica diaria.
La Sensibilidad y la Especificidad son conceptos que se
utilizan para valorar la calidad de una prueba.
Sensibilidad (S) es la capacidad que tiene un
método de reconocer a los enfermos como tales, con
respecto al “gold standard”; de modo similar, la
Especificidad (E) es la capacidad que tiene un
método de reconocer a los sujetos sanos como tales,
también, respecto del “gold standard”. Así, si
disponemos de un método “x” (asumiendo que se trata de
una prueba dicotómica, es decir, aquella que sólo puede
tener dos resultados, positivo o negativo) con una S de
87% y una E de 93% quiere decir que, si tomásemos 100
sujetos enfermos y le aplicáramos esta prueba, ella nos
daría positiva en 87; si posteriormente tomásemos 100
sujetos sanos y le realizáramos la misma prueba, esta
nos daría negativa en 93 de ellos. Podríamos
preguntarnos ahora, ¿qué ocurre con el resto? Pues bien,
13 de los 100 enfermos tendrían un resultado negativo en
la prueba, a pesar de estar realmente enfermos
(recordemos que la S de la prueba del ejemplo era del
87%) y 7 de los sujetos sanos tendrían un resultado
positivo de la prueba, pese a estar completamente sanos.
Entonces, es lógico suponer que desearíamos contar con
pruebas que tengan una S y una E del 100%, cosa que
lamentablemente NUNCA ocurre. Ahora, de lo ya expuesto
se desprende también otro interesante concepto: no
siempre los resultados obtenidos en las pruebas son los
“verdaderos”. Aquí conviene que nos detengamos un poco.
Si nos preguntaran qué resultados puede tener
una prueba dicotómica, diríamos en seguida dos, positivo
o negativo. Sin embargo, existe otra variable a
considerar: el resultado de la prueba puede ser
verdadero (es decir, coincidir con la real condición del
sujeto) o ser falso. Entonces, en realidad, los
resultados de una prueba dicotómica podrían ser cuatro,
a saber: ser un Verdadero Positivo (VP), ser un
Verdadero Negativo (VN), ser un Falso Negativo (FN) o
ser un Falso Positivo (FP). Para conocer qué capacidad
tiene una determinada prueba (entendiendo como tal no
sólo un examen complementario, sino también la presencia
de un síntoma, un signo, una maniobra semiológica
determinada, etc.) de arrojar cualquiera de los
resultados que hemos mencionado antes debemos conocer,
como hemos dicho, la S y E de la misma.
Pero ocurre que aún conociendo la S y E de un
método, frente a una persona que tenga el resultado de
una prueba, si bien podremos saber con solo observarlo
si el resultado es “positivo” o “negativo”, no podremos
dar respuesta al trascendental cuestionamiento de si ese
resultado es real (léase “verdadero”), o se trata de un
resultado “falso”. Para responder a esto contamos con
otros conceptos, los Valores Predictivos. Ellos
son dos: Valor Predictivo Positivo (VPP),
que es la probabilidad de padecer la enfermedad si se
obtiene un resultado positivo en la prueba y Valor
Predictivo Negativo (VPN), que es la
probabilidad de que una persona con un resultado
negativo en la prueba esté realmente sano. Es
interesante conocer cómo se calculan estos indicadores,
no tanto por la utilidad práctica de recordar las
fórmulas que se utilizan, sino para comprender las
implicancias de cada uno. Para esto se utiliza lo que se
denomina “tabla de contingencia”:
|
|
Enfermos |
Sanos |
|
|
Prueba + |
a
Verdaderos
Positivos |
b
Falsos Positivos |
a+b
Total de Positivos |
|
Prueba - |
c
Falsos Negativos |
d
Verdaderos
Negativos |
c+d
Total de Negativos |
|
|
a+c
Total enfermos |
b+d
Total Sanos |
a+b+c+d
Total de casos |
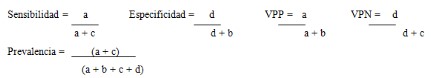
A partir de estas fórmulas, que en un primer
momento pueden parecer “complicadas”, podemos comprender
que cuanto mayor sea la S de una prueba (mayor capacidad
para detectar a los realmente enfermos, o verdaderos
positivos) menor será la tasa de sujetos con una
enfermedad que queden sin detectar, o lo que es lo mismo
que “se nos escapen” (los “falsos negativos”, personas
con la enfermedad pero en los que la prueba dio un
resultado negativo). Y de forma muy parecida, cuanto
mayor sea la E (mayor capacidad para encontrar a sujetos
sin la enfermedad como tales, o verdaderos negativos)
menos sujetos sanos serán rotulados erróneamente como
enfermos (es decir, tendremos menos “falsos positivos”).
Por todo esto se comprenderá que a la S también se la
denomine “tasa de verdaderos positivos”, ya que es un
cociente entre los positivos y los enfermos (ver fórmula
arriba) y a la E “tasa de verdaderos negativos”, puesto
que relaciona los negativos con el total de los sanos
(ver supra).
Tanto la S como la E son característica
inherentes de una prueba (es decir, son “capacidades”
propias de ellas, y no son modificables por situaciones
externas) y nos permiten valorar su utilidad; sin
embargo tienen como “desventaja” su incapacidad de
aportarnos datos concretos frente a un paciente en
particular. El VPP y el VPN nos permiten responder qué
probabilidad tiene un paciente de estar enfermo cuando
el resultado de una prueba ha sido positivo, y que
probabilidad tiene el mismo sujeto de estar sano, en
caso de que el resultado haya sido negativo. Sin embargo
tampoco son perfectos, y poseen como “desventaja” estar
íntimamente relacionados con la prevalencia de la
patología, cosa que no ocurre con S y E.
Esto quiere decir que cuando la prevalencia de una
enfermedad sea muy baja, el VPP será bajo y en cambio el
VPN será alto; y viceversa, cuando la prevalencia de la
enfermedad sea realmente elevada, el VPP será muy alto,
pero el VPN será bajo; esto es así, y varía muy poco con
los distintos valores que S y E pueden adoptar. La
demostración matemática de esto puede hacerse por medio
de las tablas de contingencia, pero escapa el propósito
del presente. Sin embargo disponemos de una forma
“visual” de recordar esto:
|
Prevalencia % |
VPP % |
VPN % |
|
99
95
90
80
50
20
10
5
1 |
99,9
99,4
98,8
97,3
90
69,2
50
32,1
8,3 |
8,3
32,1
50
69,2
90
97,3
98,8
99,4
99,9 |
Así, una prueba “x” con una S y E dada, si la
realizamos en un lugar donde la prevalencia de la
enfermedad que detecta es de 0,5% tendrá un determinado
VPP y VPN, y si posteriormente la realizamos en otro
sitio con una prevalencia de 23% de la misma patología,
los VPP y VPN serán totalmente distintos, aunque la S y
la E de la prueba se mantengan constantes.
Por todo esto, los VPP y VPN son muy útiles
frente a un paciente concreto, pero no nos aportan datos
respecto del valor de una prueba, y menos aún nos
permiten comparar diferentes pruebas entre sí. Para
“solucionar” este inconveniente se han creado otros
indicadores, que son los Likelihood Ratio (LR)
positivos y negativos (denominados en la literatura
española razones de verosimilitud o cocientes de
probabilidad -CP-). Ellos surgen de relacionar
directamente la S y la E del método, no siendo
dependientes, por tanto, de la prevalencia de la
patología. Su cálculo puede realizarse del siguiente
modo:

Los LR se definen como “multiplicadores de
chance”: sirven para comparar pruebas diagnósticas, no
dependen de la prevalencia de la enfermedad que se
busca, y pueden ser aplicados sobre pacientes en
concreto. Sin embargo, ellos también poseen una
“desventaja” y es la de no utilizar a la probabilidad
como unidad, sino a la chance.
Chance puede definirse como un cociente donde
aquello que se incluye en el numerador, queda
automáticamente excluido del denominador; al igual que
la probabilidad (unidad mucho más familiar para
nosotros) es una unidad que indica “qué posibilidad
existe de que un evento suceda”. Sin embargo chance y
probabilidad son unidades distintas, que no pueden
relacionarse entre sí de modo directo. Intentar hacerlo
sería como intentar sumar “manzanas y peras”. Entonces,
si tengo una probabilidad del 15% de padecer una
enfermedad, y tengo una prueba que si me da positiva me
multiplica en 4 las chances de padecer la enfermedad,
luego de realizar el test, si este fue positivo, mi
probabilidad aumentó, pero NO es igual a 60%, como así
tampoco si tengo 2 manzanas y 4 peras, no tengo 6 manza-peras.
Debemos aclarar que probabilidad y chance pueden
relacionarse, pero para ello debemos apelar a fórmulas,
o utilizar otros métodos, como sería el Nomograma de
Fagan. Ciertamente ninguna de las dos alternativas es
una opción práctica para nuestras actividades diarias.
Entonces, si uno maneja probabilidades ¿sirven los LR, o
multiplicadores de chance? Sí, sirven, pero hay que
saber comprenderlos y como utilizarlos, preocupándonos
menos por el cálculo de valores en sí.
Chance, como dijimos, es un cociente que indica
posibilidad. Pensemos en un dado: si lo arrojásemos con
la intención de obtener un número determinado, por
ejemplo 6, ¿cuál es la posibilidad de que ocurra lo que
deseamos? Naturalmente diríamos que tenemos una
probabilidad de 1/6, o lo que es lo mismo, 0,1667; ahora
si quisiéramos expresarlos en términos de chance, esta
sería de 0,20 (o 1/5). Quizá otro ejemplo ayude un poco
más: tengo 10 habitaciones con una persona en cada una
de ellas, y sé que 8 de esos sujetos son dislipémicos;
yo desconozco a los sujetos, pero estoy al corriente de
esta situación: ¿cuál es la posibilidad de que si yo
ingreso a una habitación, encuentre allí a un paciente
con dislipemia? Aquí nuevamente puedo calcular esta
posibilidad en términos de probabilidad o de chance,
como más lo desee. Mi probabilidad es del 0.8 u 80% ya
que tengo 8 sujetos dislipémicos, sobre un total de 10
(8/10); la chance de lograr esto mismo es aquí de 4.
¿Por qué? Porque hay 8 pacientes dislipémicos y 2 que no
lo son, es decir 8/2, lo que es lo mismo que 4. ¿Se
logra comprender dónde radica la diferencia? En la
probabilidad relaciono lo que busco respecto del total,
por ejemplo, enfermos sobre total de individuos; en
cambio cuando calculo chance relaciono (porque
recordemos que es un cociente) lo que busco sobre lo que
no busco, por ejemplo, enfermos sobre sanos. Aquí el
denominador de la fracción NO abarca el total, sino “lo
que queda” luego de excluir lo que estoy buscando.
Este es sin dudas un concepto difícil de
comprender, pero más que recordar exactamente como
obtenerlo, conviene tener presente algunos puntos:
-
La probabilidad es siempre menor a la
unidad (o si usamos la base 100%, siempre menor a esto),
en cambio la chance puede ser tanto mayor como menor que
la unidad.
-
Probabilidad y chance “hablan de lo
mismo”, aunque suele resultarnos más simple pensar en
probabilidad. A su vez, la chance tiende a “exagerar” la
posibilidad que nos muestra.
-
Chance y probabilidad no son
sinónimos, y no pueden operarse indicadores con estas
unidades de modo directo.
Ahora bien, ¿para qué nos sirve todo este embrollo
de la chance? Para entender la definición de LR, que son
multiplicadores de chance, y para recordar (al menos
luego de tanta reiteración el concepto debe quedar
arraigado) que el LR no puede usarse directamente sobre
una probabilidad. Ahora, y después de todo esto, ¿cuando
es útil un LR? De modo muy simple, cuanto más lejos de
la unidad (1) se encuentre. ¿Por qué? Porque si hablamos
de “multiplicadores”, cualquier cosa que multipliquemos
por 1 obtendremos lo mismo… Entonces si yo quiero
multiplicar (entiéndase aumentar) la posibilidad
(chance) de que un paciente tenga o no una enfermedad
luego de aplicar un test, buscaré que este genere el
mayor cambio sobre la posibilidad inicial. Así, el
cambio será mayor cuanto más grande o pequeño sea el
número por el que lo estoy multiplicando. Quizá la forma
más simple de comprender esto es con la siguiente tabla:
|
LR |
Interpretación |
|
>10 |
Aumento grande y concluyente de la
probabilidad de enfermedad. |
|
5-10 |
Incremento moderado de la probabilidad de la
enfermedad. |
|
2-5 |
Pequeño incremento de la probabilidad de la
enfermedad. |
|
1-2 |
Mínimo incremento de la probabilidad de la
enfermedad. |
|
1 |
No hay cambio en la probabilidad de la
enfermedad. |
|
0.5-1 |
Mínimo decremento en la probabilidad de la
enfermedad. |
|
0.2-0.5 |
Pequeño decremento en la probabilidad de la
enfermedad. |
|
0.1-0.2 |
Moderado decremento en la probabilidad de la
enfermedad. |
|
<0.1 |
Grande y concluyente decremento en la
probabilidad de la enfermedad. |
¿Con esto es suficiente para evaluar el valor de
una prueba diagnóstica? Casi… Si bien todo esto es
fundamental, el criterio y el buen juicio clínico son
fundamentales a la hora de valorar un test. Quizá un
ejemplo ayude a comprender mejor esta idea: un trabajo
comparó el valor de la clínica y la detección no
invasiva de H. pylori en pacientes que consultaron por
dispepsia para predecir la presencia de úlcera péptica.
Tres criterios clínicos fueron predictivos de UP: haber
padecido una ulcera péptica tuvo un LR+ de 4.6, el
tabaquismo un LR+ de 2, dolor con el estómago vacío un
LR+ de 2.8 y la detección de H. pylori un LR+ de 2.8. A
primera vista podría parecer que, con excepción del
antecedente de UP, que tendría un valor moderado,
ninguno de los demás tiene un rol importante.
Estrictamente hablando esto quizá podría ser así, pero
si prestamos atención, conocer si el paciente fuma y
preguntarle si tiene dolor con el estómago vacío son
“tests” que no poseen costos, tampoco entrañan riesgos
para la persona, están ampliamente disponibles (sólo hay
que preguntar) y son fáciles de recordar: por todo esto,
estos dos datos clínicos son útiles pese a que su LR+ no
sea el “ideal” (siempre que recordemos las limitaciones
que poseen). En cambio, la detección no invasiva de H.
pylori es costosa y aporta poco beneficios (LR+ bajo)
para este propósito, es decir, predecir la presencia de
UP en pacientes con síntomas de dispepsia; entonces,
aunque posee el mismo LR+ que tener dolor con el
estómago vacío, uno de los “tests” es útil, mientras que
el otro no.
¿Queda mucho más de esto? No, afortunadamente
casi hemos terminado…
El “gold standard” o “patrón de oro” mencionado
al principio de este texto es el método más preciso del
que se dispone para lograr el diagnóstico de una
patología determinada y, por lo tanto, es el método que
se emplea para comparar el valor de otras pruebas
diagnósticas. El “gold standard” para una patología
puede variar a lo largo del tiempo y no necesariamente
es el método que se emplea rutinariamente para lograr el
diagnóstico de certeza que se busca.
La prevalencia es la proporción de
sujetos de un grupo o una población que presentan un
evento determinado en un momento dado. La probabilidad
pretest es la prevalencia del evento o patología que se
esté investigando antes de que se lleve a cabo un test
cualquiera. Esto se relaciona con la epidemiología
(sexo, edad, prevalencia general en la población del
lugar) y con la presentación clínica; a su vez, cada vez
que apliquemos un test y este nos arroje un resultado,
la prevalencia del sujeto en cuestión habrá variado,
llamándose prevalencia postest. Pero esta prevalencia
postest se transforma en la nueva prevalencia pretest,
si vamos a realizar una nueva prueba. ¿Podrías
explicarlo de un modo más simple? Quizá un ejemplo
ayude: si una mujer de 32 años consultara por dolor tipo
angor, la prevalencia “a priori” de que se trate de un
síndrome coronario agudo es baja. Pero si al
interrogarla refiere ser diabética desde hace 20 años,
no estando controlada, ser tabaquista de jerarquía y
ser, además, hipertensa, no cumpliendo con la medicación
que le fue indicada, la prevalencia en ella varió
considerablemente respecto de su grupo según su sexo y
edad. La prevalencia pretest era inicialmente baja,
cuando sólo conocíamos unos pocos datos; luego de
interrogarla exhaustivamente respecto de sus factores de
riesgo cardiovascular (cada pregunta puede ser entendida
como un test) la prevalencia que podemos estimar en ella
sería la prevalencia postest; ahora bien, esta
prevalencia postest puede haberse incrementado
suficientemente como para que consideremos realizarle un
ECG a la paciente. Su anterior prevalencia postest es
ahora su pretest, y luego de obtener los resultados del
ECG su prevalencia habrá vuelto a variar, y será su
nueva prevalencia postest. Si aún así quisiéramos
realizarle otra prueba, su prevalencia postest pasa a
ser la nueva pretest, hasta que se obtenga una nueva
postest. Y así sucesivamente… Pero, ¿y cuándo nos
detenemos? Dejaremos de hacer pruebas cuando la
probabilidad de que el paciente esté enfermo sea
suficientemente elevada como para autorizarnos a actuar
al respecto, o sea tan baja que podamos estar seguros
que no padece la enfermedad. De modo gráfico:

Cabe preguntarnos, con tantos cálculos y
fórmulas en el texto ¿realmente debemos “sentarnos a
hacer números” o debemos preocuparnos más bien por
atender pacientes? La verdad es que todos estos
conceptos son teóricos, pero nos permiten llevar a cabo
un razonamiento más crítico y que redundará en beneficio
de nuestros pacientes. Sin embargo esto no implican que
debamos intentar “calcular” exactamente la probabilidad
de un paciente de padecer una patología. Esto es algo
que suele estimarse “a ojo” ya que en la práctica, no
hay diferencias entre una probabilidad de 21, 27 o 32%.
Para ir terminando, y luego de todo esto podemos
preguntarnos, si deberíamos optar entre una prueba muy
sensible pero menos específica, o una prueba muy
específica pero menos sensible, ¿qué es lo más adecuado?
Podemos decir que la selección de un test diagnóstico
dependerá, en primer lugar, de su valor intrínseco
(según los parámetros sobre los que hemos estado
hablando), también de la prevalencia calculada de la
enfermedad y en gran medida de cuál es nuestro objetivo
diagnóstico. Si queremos realizar un screening, es
decir, captar la mayor cantidad de sujetos con una
determinada enfermedad utilizaremos pruebas muy
sensibles, aún sabiendo que así incluiremos a algunos
sanos en este grupo; ahora, si lo que buscamos es
confirmar una enfermedad, queremos asegurarnos que
ningún sujeto sano sea rotulado erróneamente como
enfermo (y, por tanto, que sea tratado como tal). En
este caso elegiremos las pruebas con mayor
especificidad, aunque con esto “quede sin incluirse”
algún paciente con la enfermedad.
Resta aún aclarar un concepto fundamental, el de
Intervalo de Confianza (IC). Cuando tratamos de
establecer algo, (cualquier cosa, desde la sensibilidad
de un método hasta la seguridad o utilidad de un
fármaco) no sólo buscamos “conseguir” un valor, tratamos
también de determinar que aquello que hemos afirmado se
asemeja en la mayor medida posible a la realidad, y no
es mero fruto del azar. Ciertamente pretender que lo que
decimos sea “la realidad” o “la verdad” es algo
ambicioso, pero no cabe duda de que debemos intentar que
se encuentre lo más cercana posible a ella. Entonces,
los IC pueden ser definidos como la expresión
estadística del grado de confiabilidad del dato que
estamos informando o, de un modo más coloquial, “qué
tanto se aproxima el resultado que hemos hallado a la
realidad”. Quizá un ejemplo permita comprender aún mejor
esto: supongamos que un trabajo informa que una prueba
“x” tiene un LR+ 9 (IC 95 0,9 - 15,2). No cabe duda que
el LR informado es casi excelente pero, ¿qué nos quiere
decir su IC? En primer lugar, el número que le sigue
indica la probabilidad con la que se establecen los
límites del intervalo, habitualmente se emplea 95% o 99%
(lo que implica un margen de error del 5% o 1%,
respectivamente). Segundo, nos dice que hay una
probabilidad del 95% (o la que hallamos elegido) de que
el LR real de la prueba sea un valor comprendido en el
intervalo limitado por el rango 0,9 a 15,2. De un modo
más simple, en el mejor de los casos la prueba puede ser
tan buena como tener un LR de 15,2, pero en el peor de
los casos sería tan inútil como si tuviera un LR+ de
0,9; y esto lo podemos afirmar con una confianza del 95%
o, lo que es lo mismo, si repitiéramos 100 veces el
trabajo para el cálculo del LR, en 95 de ellos se espera
que el valor hallado se encuentre dentro del intervalo
de confianza dado. Un IC será tanto más útil cuanto más
estrecho sea, ya que esto implica mayor precisión del
dato brindado; por otra parte, si un IC “cruza” la
unidad (como en nuestro ejemplo) o “cambia de signo” (es
decir, es positivo uno de sus extremos y negativo el
otro) el dato brindado carece absolutamente de valor.
¿Por qué? Porque al analizar algo, lo que buscamos es
saber “en qué grupo se encuentra”; en nuestro ejemplo
queríamos saber si el LR era útil o no, si habláramos de
una droga querríamos saber si es beneficiosa o
perjudicial, etc. Y que el IC “cruce” la unidad implica
que el valor real de lo que tratamos de estimar puede
encontrarse tanto a un lado como al otro, o lo que es lo
mismo, en un grupo o en su opuesto. Volvamos a nuestro
ejemplo: si el LR tiene un IC 95 0,9 a 15,2 puede
ocurrir que un resultado positivo en la prueba me
incremente la posibilidad de que el paciente esté
enfermo (que es lo que realmente estamos buscando), cómo
así también que un resultado positivo haga que sea menos
probable que la persona padezca la enfermedad (un LR+
0,9 en realidad disminuye la posibilidad, ¡en vez de
incrementarla!). En ese último caso cualquiera puede
inferir la falta de utilidad de la prueba.
Si utilizáramos como ejemplo el beneficio de un
fármaco, que el IC atraviese la unidad (o cambie de
signo, según cómo se estén expresando los resultados)
significaría que no es posible afirmar que la droga sea
beneficiosa o perjudicial para el uso que se le pretende
dar. Aquí es quizá más evidente el peligro de la misma,
independientemente del valor que se haya encontrado y de
la amplitud del IC (es decir, por más estrecho que sea,
si atraviesa la unidad el IC no es útil).
Conclusiones:
ü
Sensibilidad y Especificidad nos hablan de “que tan
buenas” son las pruebas diagnósticas, pero no nos
permiten predecir resultados frente a un paciente
concreto.
ü
Cuando la prevalencia pre-test sea muy baja, una prueba
negativa me descartará la patología, pero una positiva
no podrá aún confirmármela (VPN muy alto, pero VPP bajo)
y viceversa; cuando la prevalencia pre-test sea alta, un
resultado positivo me confirmará la hipótesis, pero un
resultado negativo no podrá excluírmelo totalmente.
ü
Chance y probabilidad “hablan de lo mismo”, pero lo
hacen de modo “diferente”, con lo cual no pueden
relacionarse de modo directo.
ü
LR son multiplicadores de chance; su utilidad es tanto
mayor cuanto más alejados del 1 se encuentren; sin
embargo, no solo debemos utilizar este parámetro para
estimar el valor de un test.
ü
Cuando necesitemos hacer un screening deberemos utilizar
pruebas con la mayor sensibilidad posible; en cambio,
cuando la intención sea confirmar un diagnóstico
deberemos utilizar las pruebas con mayor Especificidad
posible.
ü
Los IC son tanto mejores cuanto más angostos son, y
siempre que un IC atraviese la unidad carece de valor
real.
Referencias
1- Reussi R. (2.002)
Evidencias en Medicina Interna. De la evidencia
científica al arte de la consulta. Roberto Reussi.
1º Edición. Buenos Aires, Edición Fundación Reussi.
2- Doval H.C., Tajer
C. D. (2.005) Evidencias en Cardiología IV. De los
ensayos clínicos a las conductas terapéuticas. 4º
Edición. Buenos Aires, Editorial Atlante - Gedic.
3- Bottasso O. Lo
esencial en Investigación Clínica. Una introducción a
las ciencias biológicas y médicas. 2º Edición.
Rosario, Editorial Corpus.
4- Pita Fernández
S., Pértegas Diaz S. Pruebas Diagnósticas. En
www.fisterra.com
5- Molinero L. M.
Valoración de Pruebas Diagnósticas. Asociación
Española de Hipertensión, Liga Española para la lucha
contra la Hipertensión Arterial. En
www.seh-lelha.org
6- Como leer un
artículo de diagnóstico. Parte 1. Capítulo 9. Curso
Introductorio de Medicina Basada en la Evidencia. En
www.intramed.net
|
|
|




